
RAFT: When RAG meets Supervised Fine-Tuning

Introduction
As LLMS are being deployed in more specialized domains (i.e., legal, medical, etc), maximizing accuracy in the domain is more critical than general knowledge reasoning. So far, there have been two main solutions for adapting LLMs to specialized domains: a) Retrieval Augmented Generation (RAG) with in-context learning, and b) Supervised Fine-Tuning (SFT). However, both of them come with limitations. RAG fails to leverage the learning opportunity afforded by the fixed domain setting and early access to the test documents, while SFT fails to leverage documents at test time.
Retrieval-Augmented Fine-Tuning (RAFT) is a novel training strategy designed to enhance the performance of LLMs for domain-specific question-answering tasks. RAFT aims to bridge the gap between traditional retrieval-augmented generation (RAG) and supervised fine-tuning, creating a powerful model that can seamlessly incorporate external knowledge while retaining strong reasoning skills.
Approach
LLMs and Closed-Book Exam
The RAFT recipe is inspired by the open-book exam analogy where there are three main options (Fig. 1) :
Closed-Book Exam: Supervised Fine-Tuning solutions simulate “studying” by memorizing the material. The LLMs respond to the prompt based on the pre-baked knowledge during pre-training and supervised fine-tuning
Open-Book Exam: Traditional RAG systems are akin to taking an exam without studying but they have access to external sources of information. In this case, the LLM has access to new knowledge via the new documents that are retrieved by the retriever. So, the performance of these systems largely depends on the performance of the retriever.
Domain-Specific Open-Book Exam: RAFT simulates the process of studying for an open-book exam by training the model to recognize relevant and irrelevant information from retrieved documents. The domain in which the LLM will be tested is known priori (examples include enterprise documents, latest news, code repositories belonging to an organization, etc)

RAFT
The key aspects of the RAFT training process are (Fig. 2):
Document Selection: P fraction of the questions (q) in the dataset have both the oracle documents and the distractor documents. The remaining (1 − P ) fraction of the questions, doesn’t include any oracle document pushing the model to memorize answers instead of deriving them from context.
Answer Generation: The model is trained to generate a chain-of-thought style answer A* that incorporates verbatim citations from the relevant D* documents to justify the final answer.
Handling Distractors: By including distractor documents during training, RAFT forces the model to learn to identify and ignore irrelevant information while focusing on extracting insights from the truly relevant sources.
The training dataset is used to train the model with the standard SFT technique. At test time, RAFT follows the standard RAG setup; given a query Q, a retriever provides the top-k potentially relevant documents, which are appended to the prompt (Fig. 2). However, thanks to its specialized training regimen, the RAFT model is better equipped to extract relevant information from the provided documents while ignoring distractors.

In more detail, in a question-answering setting where we have a dataset (D) from which a set of Question (Q) and corresponding answer (A) pairs are derived, SFT and RAG methods can be represented as follows:

RAFT formulation for the same QA setting prepares the dataset (D) so that each data point in the training data contains a question (Q), a set of documents (D_k), and a corresponding Chain-of-though style answer (A∗) generated from the oracle documents (D∗). The recipe also considers distractor documents that do not contain the relevant information. In this setting, an example RAFT training instance is:

One key factor for the success of RAFTA is that it leverages chain-of-thought prompting, encouraging the model to generate step-by-step reasoning explanations that justify its answers. This approach not only enhances the model's transparency but also improves its ability to reason effectively.
Evaluation
RAFT was evaluated across various datasets, including PubMed (biomedical literature), HotpotQA (multi-hop Wikipedia questions), and the Gorilla API Bench (software documentation). Their results consistently demonstrated RAFT's superiority over baselines, such as domain-specific fine-tuning with and without RAG, and even larger models like GPT-3.5.
Across all these diverse domains, RAFT consistently outperformed several strong baselines:
GPT-3.5 with retrieval augmentation
Standard language model (e.g. LLaMA) with and without retrieval
Domain-specific fine-tuning of the LM, with and without retrieval augmentation
The performance gains against Llama2 with RAG were particularly impressive on certain datasets like HotpotQA (up to 35.25% improvement) and Torch Hub evaluation from Gorilla API Bench (up to 76.35% improvement).

Training with chain-of-thought responses provided a significant boost. On HotpotQA, adding chain-of-thought improved performance by 9.66%, while on HuggingFace datasets performance improved by 14.93%.

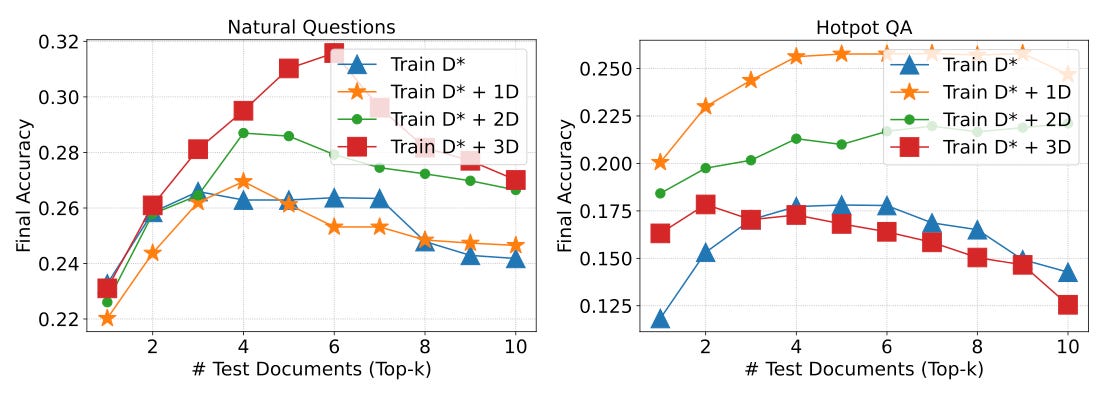
Fine-tuning with 20% of oracle documents in the context improves the model performance (Fig. 3). Similarly, distractor documents are also important to model performance. It was found that the model performance was better when the model was trained with 2-4 distractor documents (Fig. 4).

Conclusion
RAFT represents a significant step forward in adapting LLMs for domain-specific question-answering tasks. By combining the strengths of fine-tuning and RAG, RAFT equips LLMs with both domain-specific knowledge and the ability to effectively leverage external information sources. As the demand for specialized language models continues to grow, RAFT provides a promising solution for improving their performance in open-book settings.
References
[1] T. Zhang, S. G. Patil, N. Jain, S. Shen, M. Zaharia, I. Stoica, and J.E. Gonzalez, RAFT: Adapting Language Model to Domain Specific RAG, https://arxiv.org/pdf/2403.10131.pdf
[2] https://gorilla.cs.berkeley.edu/blogs/9_raft.html